KV 存储
KV 存储是现代数据库的基石,不论是索引,元数据,还是 KV 数据库本身,都会用到 KV 存储的数据结构。在编程语言中,往往会内置一些支持 KV 的数据结构,例如 Java 的 Map<K, V> 或者 Python 的 dict。而在数据库中,KV 还需要考虑到磁盘 IO 特点(我们总是希望顺序 IO),以及高可用等,往往需要更加复杂一些的处理。
LSM-KVS
LSM-KVS 基于 LSM(Log Structured Merge Tree) 实现 KV 存储。这种设计由几个部分组成。
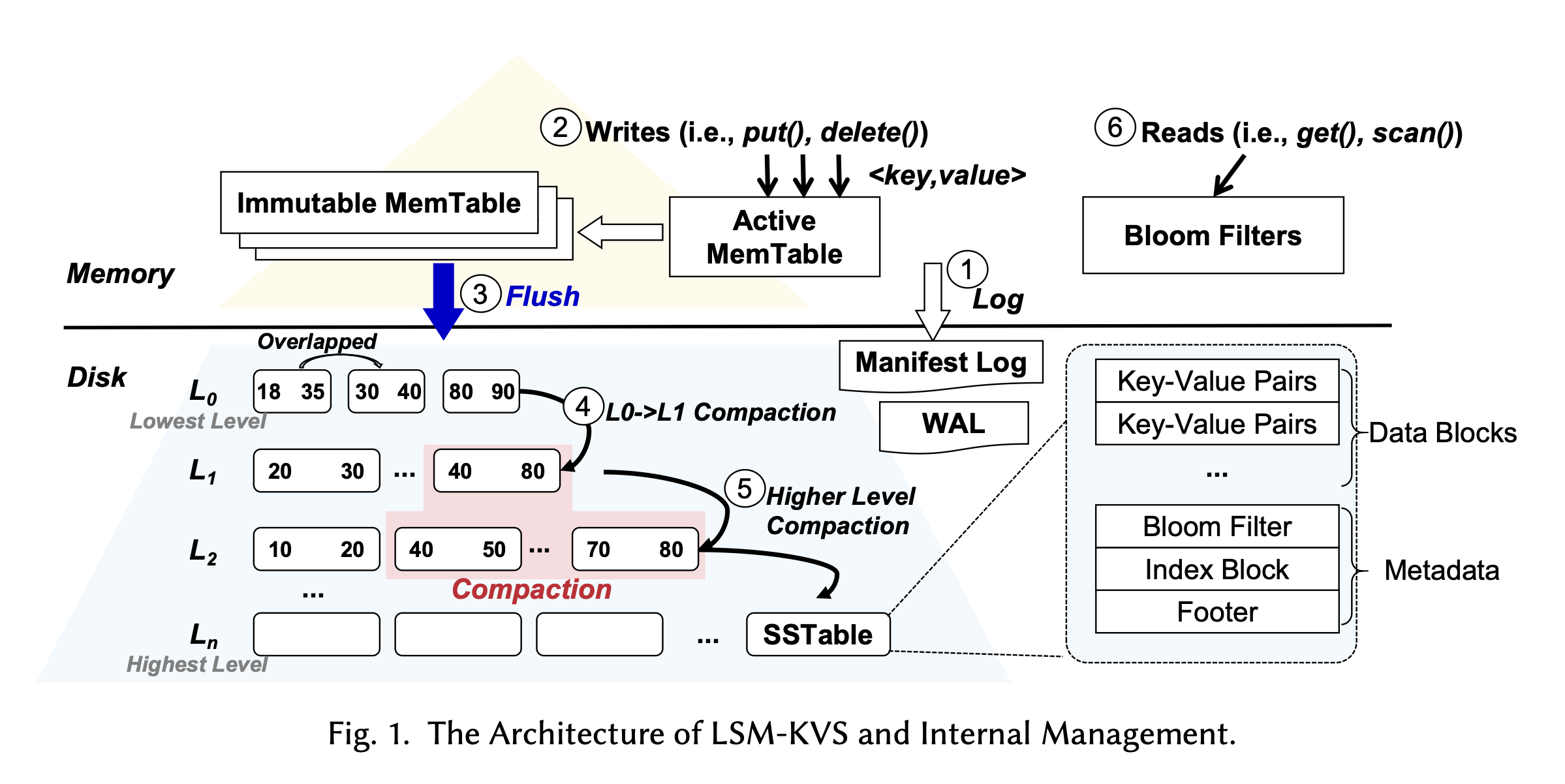
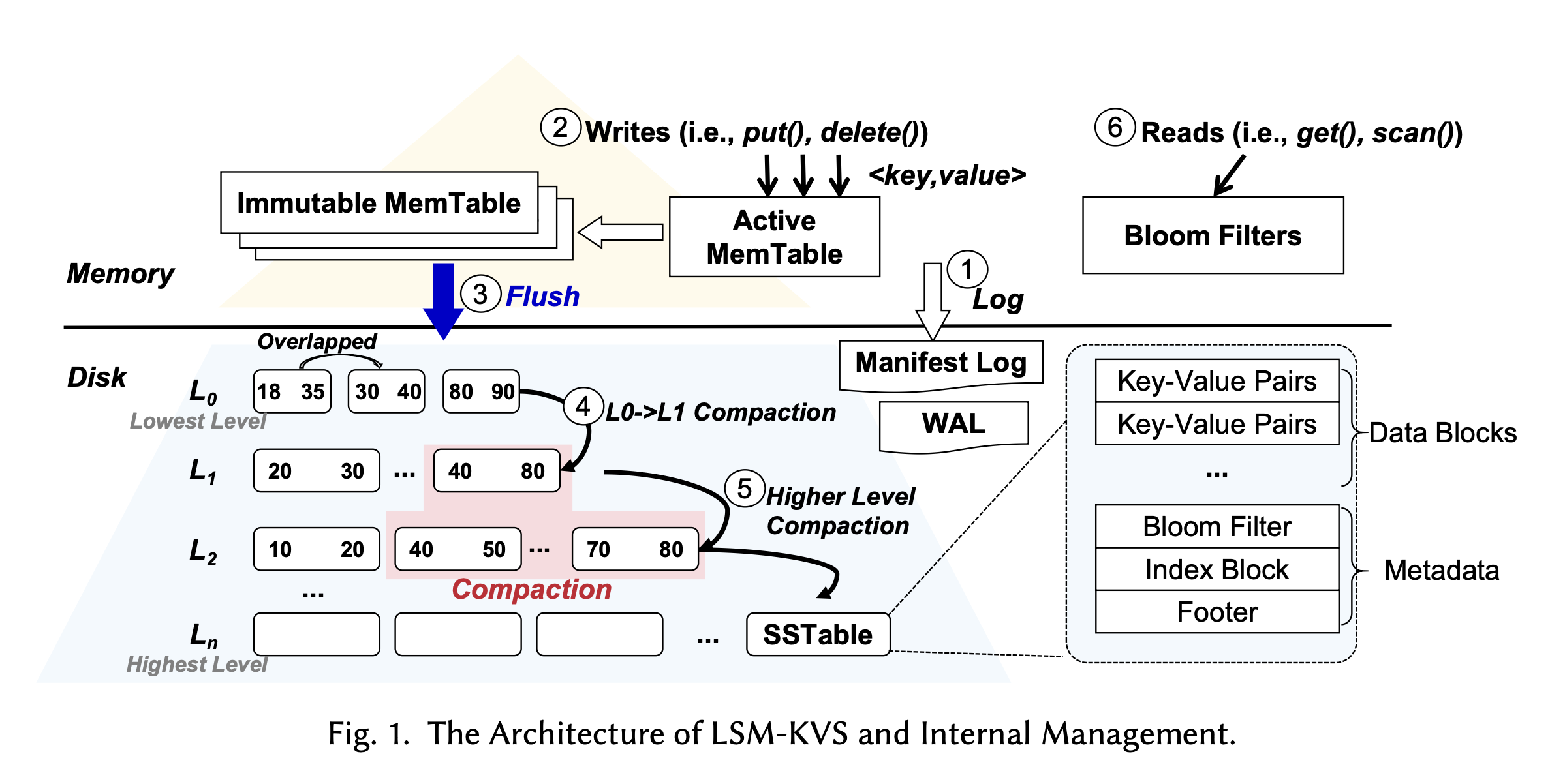
Mem Table
Mem Table 就是内存中的 Hash 数据结构。LSM 一般会有一个 Mem Table 来进行实时的写入操作(相当于缓冲区),由于这些行为发生在内存中,所以速度非常快。当满足一定条件时(Mem Table 大小达到了阈值,或者到了一定时间),Mem Table 被 Flush 到磁盘上。从架构图可以看出,磁盘上的数据段是分层的,Flush 只会将 Mem Table 刷到最低层。
Flush 的行为可以是异步的,但是它对正在进行的写操作是有影响的,所以会导致吞吐量的下降。
WAL
除了 Mem Table 最终会 Flush,还有一个要落盘的就是 WAL。WAL 在每次写入时候都会落盘,因为它是用来保证数据恢复的。但是为了性能,可能是需要对 WAL 进行批量操作,来减少磁盘 IO。
SSTable(Sorted String Table)
SSTable 是 Mem Table 落盘后的形态,由若干数据段(Segment)组成。
SSTable 结构
Segment 中包含了
- 稀疏索引:存放 Key 的子集,以及他们在磁盘文件中的偏移量。
- 顺序 KV 对。
- Bloom Filter:用于快速判断某个 Key 是否一定不在这个 Segment 中。
Segment 是按照时间来划分的,比如今天 12:00 - 13:00 存在
seg-1.sst, 13:00 - 14:00 存在seg-2.sst,并且 Segment 之间是存在 Key 重合的,比如我在两个时间段写入了k=v1,k=v2,那么这两组 KV 对会存在两个 Segment 中。
查询
在查询 SSTable 时,我们从最新的 Segment 开始
- 查看 Bloom Filter
- 查询稀疏索引,如果能查到,则直接通过 Offset 获取数据,否则返回一个区间
- 在区间内顺序扫描 Key
合并 (Merge)
多个带有重复 key 的 SSTable 合并时,我们会舍弃旧 SSTable 中的 Key 而保留新的。这种操作类似于 merge-sort 中的 merge,通常会使用 Iterator 来做。
连接 (Join)
多个没有重复 key 的 SSTable 合并时,我们不需要进行 merge,而只需要进行简单的合并(SSTable 内部已经排好序了,所以直接追加数据就能实现 join)。
Level
从架构图我们可以发现,LSM 的 SSTable 通常被组织成不同的层。当 Flush 发生时,MemTable 总是被刷到 L0,因此 L0 的 SSTable 之间是存在 Key 重叠的。 重复的 Key 会导致读放大(Read Amplification):当我需要读取过去某个 Key 值的时候,系统可能需要扫描所有的 SSTable 才能找到它,会非常慢,因此需要引入一个 Compaction 的流程,对数据段进行合并。L1 及以上的 SSTable 都是被整理过的,因此不存在 Key 重叠,在查询时,可以直接命中。
层内整理 (Intra-Level Compaction)
有些数据库的实现会在 L0 内部进行 in-place 的整理,例如 Ocean Base
低层整理(Low-Level Compaction)
低层整理一般是 (L0 -> L1)的整理,当 L0 的 SSTable 数量达到阈值时会触发。低层整理的行为是 Merge。
High Level Compation
高层的整理会涉及到合并多个层的 SSTable。如架构图所示,它会选定一个 k 层的 SSTable,在 k+1 层找到和它 key 重合的 SSTable,把它们加载到内存中,然后进行一个 join-merge 操作:即对 k+1 层的 SSTable 进行 join,再与 k 层的 SSTable 进行 merge。
LSM KVS 查询
有了上面的介绍,查询的逻辑就比较清楚了。
- 从 MemTable 进行查询
- 如果没找到,从磁盘上进行查询:从 L0 开始 a. 对于 L0 层,需要从新到旧遍历 SSTable 查询 key b. 对于更高层,只需要根据 key 范围定位到 SSTable 以后从中查询
分布式 LSM-KVS
分布式的 LSM-KVS 系统架构如下
 和很多分布式系统类似,它引入了
和很多分布式系统类似,它引入了
- Coordinator
- 分片(一致性哈希)
- 复制(Raft,Paxos 等等)
机遇和挑战
资源分配。
LSM 系统的一大挑战是数据整理阻塞写入。有一些尝试的方向
- 限流:控制系统写入的流量,防止 Compaction 引起的过载。然而,限流的方式有可能会使得积压越来越多的写请求。
- Latency 预测:通过预测磁盘 IO 的延迟,在可预测的时间窗口内阻塞写入请求。
- 多线程 Compaction:通过系统负载,动态调整 Compaction 的线程数量
IO 调度
- 调度 Flush 和 Compaction 任务,减少它们和读请求之间的影响 (Vigil-KV)
- 利用 NVMe 硬件的 IO 延时可预测的特性进行优化
- 将上层 SSTable 和 WAL 日志放到空间更小,但是速度更快的硬盘上(SpanDB)
自动调优
LSM 系统有大量的参数,例如 Compaction 策略,磁盘文件 Layout,MemTable 大小等等。通过强化学习等技术来动态调整参数,也是一种方式(如 Dremel)
Compaction 优化
- 何时触发?
- 整理那些 SSTable?
- Compaction 粒度?更小的粒度会有更多 IO,但是单次停顿时间更短
- Data Layout:Leveling VS Tiering
- In-Storage Compaction:使用专有硬件(GPGPU,FPGA),直接在存储层进行数据整理,节省 CPU 的时间。
KV 操作优化
TODO